Programmiersprachen wie z.B. C++ unterscheiden sich gegenüber Java dadurch,
dass sie in Maschinencode für einen fest vorgegebnen Prozessortyp übersetzt werden.
Java-Quelltext hingegen wird u.a. in in einen plattformunabhängigen Zwischencode
übersetzt, der als Java-Bytecode oder kurz Bytecode bezeichnet wird. Der Bytecode
enthält Maschinenbefehle für einen virtuellen (erdachten) Prozessor, wobei solche
Prozessoren bereits konkret realisiert wurden. Der Bytecode steht in der sogenannten
Klassendatei, die nach der Compilierung mit einem Java-Compiler (z.B. javac)
aus dem Java-Quelltext erzeugt wird. Die Ausführungseinheit des Bytecodes wird als
Java Virtual Machine (JVM) bezeichnet und besitzt u.a. wie
ein realer Prozessor einen Befehlssatz (Bytecode).
Compiler Quellprogramm ----------------> Zielprogramm (z.B. Assemblersprache, Bytecode oder Maschinensprache) Quellprogramm: Assemblersprache (Mnemonik): Bytecode (Operationscode): int j = 0; iconst_0 03 (00000011) istore_0 3b (00111011) j = j + 2; iload_0 1a (00011010) iconst_2 05 (00000101) iadd 60 (01100000) istore_0 3b (00111011)
Ein in Assemblersprache geschriebenes Programm wird durch einen Assembler,
der wiederum als Compiler bezeichnet wird, in Maschinencode übersetzt. Die
Assemblersprache ist eine von der real existierenten Hardware (verwendeter Mikroprozessor)
stark abhängige Sprache (für unterschiedlich entwickelte Prozessoren gibt es oftmals
verschiedene Assemblersprachen). Dies liegt daran, dass Assemblersprache nahezu
direkt auf einen zum Prozessor "passende" Maschinensprache abgebildet wird.
Maschinensprache (Maschinencode) besteht aus einer Abfolge von einzelnen Nullen
und Einsen und ist i.a. schwer für den Menschen lesbar. Jeder gültigen Bitfolge
wird daher ein Name (Mnemonik) zugeordnet. Diese Mnemoniks werden durch einen
Assembler nahezu 1:1 in Maschinencode übersetzt. Ein Maschinencode ist der Befehlssatz
für einen speziellen Mikroprozessor und ist sozusagen die "Muttersprache" des Prozessors.
Hinter dem Maschinencode der Java Virtual Machine (JVM) 01100000 für
die Mnemonik iadd kann eine konkrete "Verdrahtung" (Mikroelektronik)
stehen.
Übersetzter für einfache arithmetische Ausdrücke
Mit Hilfe des einfachen Beispiel-Compilers aus Listing 4.1 können einfache arithmetische Ausdrücke, wie z.B.
3 + 7 * 5 - 9 / 3
in gültigen Java-Bytecode übersetzt werden. Da der Übersetzter einfach gehalten ist, wäre folgendes zu beachten:
-
Es können nur die einzelnen Ziffern 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 benutzt werden, also keine zweistellige Zahl (z.B. 12) oder Dezimalzahlen (z.B. 3.14).
-
Die bekannten Operatoren +, -, *, / können verwendet werden.
-
Innerhalb der Ausdrucks dürfen keine Leerzeichen enthalten sein.
-
Bei einer Division wird ein möglicher Nachkommaanteil nicht beachtet, da bei der Übersetzung in Java-Assemblersprache nur Integer-Befehle (z.B. iadd, idiv) genutzt werden (z.B. ist 9/4 = 2).
-
Klammern "( )" können nicht verwendet werden.
Für die einzelnen Ziffern und für das Ergebnis der Berechnung werden (lokale) Variablen zur Verfügung gestellt. Der oben stehende Beispielausdruck würde konkret in einem lauffähigen Java-Quellcode wie folgt lauten (hervorgehoben dargestellt):
public class Test {
public static void main(String[] args) {
int a = 3;
int b = 7;
int c = 5;
int d = 9;
int e = 3;
int f = a + b * c - d / e;
}
}Ohne Verwendung von Variablen für die einzelnen Ziffern, würde der Java-Compiler
javac das Ergebnis der Berechnung bereits während der Übersetzung
ermittlen und im Bytecode würde sich dann nur das Endergebnis wiederfinden. Die
Beispielklasse Test kann nun mit Hilfe des im JDK enthaltenen Compilers
übersetzt werden. Die dadurch enstandene Klassendatei hat ca. 304 Bytes (abhängig
von der Compiler-Vesion bzw. der Version des JDK). Ein Teil dieser 304 Zahlenwerte
(die Zahlenwerte sollen als Integer-Werte ausgewertet werden und liegen daher im
Bereich von 0 bis 255) sollen durch den Beispiel-Compiler aus
Listing 4.1 genauso generiert werden, wie sie durch Verwendung
von javac erzeugt werden, falls die genannten Voraussetzungen für
arithmetische Ausdrücke beachtet werden. Mit Hilfe der folgenden Anweisungen können
die Ganzzahlen, aus denen sich die Datei Test.class zusammensetzt, der
Reihe nach auf dem Bildschirm angezeigt werden:
import java.io.*;
public class Test2 {
public static void main(String[] args) {
int data;
try {
FileInputStream in = new FileInputStream("Test.class");
while ((data = in.read()) != -1) {
System.out.print(data + " ");
}
in.close();
} catch (Exception e) {
System.out.println(e.toString());
}
}
}Dabei sind die Zahlenwerte, die auch durch den einfachen Beispiel-Übersetzter erzeugt werden sollen, hervorgehoben dargestellt:
202 254 186 190 0 0 0 49 0 15 10 0 3 0 12 7 0 13 7 0 14 1 0 6 60 105 110 105
116 62 1 0 3 40 41 86 1 0 4 67 111 100 101 1 0 15 76 105 110 101 78 117 109 98
101 114 84 97 98 108 101 1 0 4 109 97 105 110 1 0 22 40 91 76 106 97 118 97 47
108 97 110 103 47 83 116 114 105 110 103 59 41 86 1 0 10 83 111 117 114 99 101
70 105 108 101 1 0 9 84 101 115 116 46 106 97 118 97 12 0 4 0 5 1 0 4 84 101
115 116 1 0 16 106 97 118 97 47 108 97 110 103 47 79 98 106 101 99 116 0 33 0
2 0 3 0 0 0 0 0 2 0 1 0 4 0 5 0 1 0 6 0 0 0 29 0 1 0 1 0 0 0 5 42 183 0 1 177 0
0 0 1 0 7 0 0 0 6 0 1 0 0 0 1 0 9 0 8 0 9 0 1 0 6 0 0 0 76 0 3 0 7 0 0 0 28
6 60 16 7 61 8 62 16 9 54 4 6 54 5 27 28 29 104 96 21 4 21 5 108 100 54 6
177 0 0 0 1 0 7 0 0 0 30 0 7 0 0 0 3 0 2 0 4 0 5 0 5 0 7 0 6 0 11 0 7 0 14 0 8
0 27 0 9 0 1 0 10 0 0 0 2 0 11Die genannten Ganzzahlen (dezimale Schreibweise) können in die binäre bzw. hexadezimale Schreibweise überführt werden. Der Beispiel-Compiler gibt die erzeugten Bytes in hexadezimaler Notation aus. Die Zahlenwerte 6, 60, 16 und 7 lauten z.B. in binärer und hexadezimaler Formulierung wie folgt:
dezimal binär hexadezimal 6 00000110 06 60 00111100 3c 16 00010000 10 7 00000111 07
Das folgende Listing entspricht einem einfachen Compiler, der arithmetische
Ausdrücke (unter Beachtung von einigen Bedingungen) in Java-Assemblersprache und
Java-Bytecode übersetzt. Die einfachen arithmetischen Ausdrücke können als sehr
kleine Teilmenge der umfassenden Programmiersprache Java angesehen werden. Dieser
sehr eingeschränkte Java-Quellcode wird aber genauso wie durch Verwendung von
javac übersetzt.
Listing 4.1. SimpleCompiler.java. Einfacher Compiler, der einfache arithmetische
Ausdrücke in Assemblersprache und Bytecode übersetzt.
/* SimpleCompiler.java */ public class SimpleCompiler { char lookahead; char[] expression; int index = 0; int start_local_variable = 1; int local_variable = start_local_variable; int marker = 0; StringBuffer postfix = new StringBuffer(); StringBuffer mnemonics = new StringBuffer(); StringBuffer bytecode = new StringBuffer(); public SimpleCompiler(String s) { expression = s.toCharArray(); lookahead = expression[0]; expr(); System.out.println("Ausdruck in Postfixnotation:"); System.out.println(postfix.toString() + "\n"); getMnemonicsAndBytecode(); System.out.println("Compilierter Ausdruck in Assemblersprache:"); System.out.println(mnemonics.toString() + "\n"); System.out.println("Compilierter Ausdruck in Bytecode (hexadezimal):"); System.out.println(bytecode.toString()); } public String toHexString(int i) { String s = Integer.toHexString(i); if (s.length() == 1) { s = "0" + s; } return s; } public void error() { System.out.println("Syntaxfehler!"); System.exit(2); } public void match() { index++; if (index < expression.length) { lookahead = expression[index]; } } public void digit() { if (Character.isDigit(lookahead)) { postfix.append(lookahead); } else { error(); } match(); } public void term() { digit(); while(true) { switch(lookahead) { case '*': match(); digit(); postfix.append("*"); break; case '/': match(); digit(); postfix.append("/"); break; default: return; } } } public void expr() { term(); while(true) { switch(lookahead) { case '+': match(); term(); postfix.append("+"); break; case '-': match(); term(); postfix.append("-"); break; default: return; } } } public void getMnemonicsAndBytecode() { char c; // Operanden in lokale Variablen speichern for (int i = 0; i < postfix.length(); i++) { c = postfix.charAt(i); if (Character.isDigit(c)) { int a = Character.getNumericValue(c); if (a < 6) { mnemonics.append("iconst_" + c + "\n"); bytecode.append(toHexString(3 + a) + " "); } else { mnemonics.append("bipush " + c + "\n"); bytecode.append("10 " + toHexString(a) + " "); } if (local_variable < 4) { mnemonics.append("istore_" + local_variable + "\n"); bytecode.append(toHexString(59 + local_variable) + " "); local_variable++; } else { mnemonics.append("istore " + local_variable + "\n"); bytecode.append("36 " + toHexString(local_variable) + " "); local_variable++; } } } // Operationen auswerten local_variable = start_local_variable; for (int i = 0; i < postfix.length(); i++) { c = postfix.charAt(i); if ((c == '*') || (c == '/') || (c == '+') || (c == '-')) { // lokale Variablen laden for (int j = marker; j < i; j++) { if (local_variable < 4) { mnemonics.append("iload_" + local_variable + "\n"); bytecode.append(toHexString(26 + local_variable) + " "); } else { mnemonics.append("iload " + local_variable + "\n"); bytecode.append("15 " + toHexString(local_variable) + " "); } local_variable++; marker++; } if (c == '*') { mnemonics.append("imul\n"); bytecode.append("68 "); } if (c == '/') { mnemonics.append("idiv\n"); bytecode.append("6c "); } if (c == '+') { mnemonics.append("iadd\n"); bytecode.append("60 "); } if (c == '-') { mnemonics.append("isub\n"); bytecode.append("64 "); } marker++; } } // Ergebnis in lokale Variable if (local_variable < 4) { mnemonics.append("istore_" + local_variable); bytecode.append(toHexString(59 + local_variable) + " "); } else { mnemonics.append("istore " + local_variable); bytecode.append("36 " + toHexString(local_variable) + " "); } } public static void main (String[] args) { String str = ""; if (args.length == 1) { str = args[0]; } else { System.out.println("usage: java SimpleCompiler <infix-expression>"); System.exit(1); } SimpleCompiler sc = new SimpleCompiler(str); } }
Der einfache Compiler kann z.B. mit folgendem Beispielaufruf gestartet werden:
> java SimpleCompiler 3+7*5-9/3
Nach dem Kommando wird im Beispiel eine Ausgabe wie folgt erzeugt:
Ausdruck in Postfixnotation: 375*+93/- Compilierter Ausdruck in Assemblersprache: iconst_3 istore_1 bipush 7 istore_2 iconst_5 istore_3 bipush 9 istore 4 iconst_3 istore 5 iload_1 iload_2 iload_3 imul iadd iload 4 iload 5 idiv isub istore 6 Compilierter Ausdruck in Bytecode (hexadezimal): 06 3c 10 07 3d 08 3e 10 09 36 04 06 36 05 1b 1c 1d 68 60 15 04 15 05 6c 64 36 06
Die Schreibweise des arithmetischen Ausdrucks "3+7*5-9/3" wird als
Infixnotation bezeichnet. Daneben wird auch die sogenannte
Postfixnotation (auch: "Umgekehrte Polnische Notation" (UPN))
verwendet, die den Vorteil einer stapelbasierten Abarbeitung vorweist. Die Postfixnotation
des verwendeten Ausdrucks würde z.B. "375*+93/-" lauten. Eine stapelbasierte Berechnung
des Ausdrucks kann technisch relativ einfach realisiert werden (z.B. bei Taschenrechnern
bzw. Computern). Bei dieser Schreibweise weden zunächst einige Zahlen (Operanden)
der Berechnung auf einen Stapel abgelegt. Im Beispiel befinden sich zunächst die
Zahlen 3, 7 und 5 auf dem Stapel, wobei die 5 an oberster Stelle liegt. Der Operator
"*" ist zweistellig und damit werden die zwei Zahlen 5 und 7 vom Stapel geholt und
miteinander multipliziert. Das Ergebnis 35 dieser Operation wird wieder auf den
Stapel gelegt. Der nächste Operator der UPN holt die beiden Zahlen 35 und 3 vom
Stapel und addiert diese. Das Ergebnis 38 wird wiederum auf den Stapel gelegt. Die
stapelbasierte Abarbeitung wird nun solange fortgesetzt bis der letzte Operator "-"
zur Anwendung kommt. Das Endergebnis liegt danach als einzige Zahl auf dem Stapel.
In der UPN wird die Vorangregel "Punkt vor Strich" bereits beachtet (der
Multiplikationsopertor "*" steht vor dem Operator "+" und der Divisionsoperator "/"
steht vor dem Operator "-"). Der Beispiel-Compiler ermittelt zunächst die UPN des
in einer Kommandozeile der Konsole eingegebenen Ausdrucks in Infixnotation. Danach
erfolgt die Umsetzung der UPN in einzelne Mnemoniks bzw. Assemblersprache. Als
nächstes kann relativ einfach einer bestimmten Mnemonik ein Operationcode der
virtuellen Java Maschine zugeordnet werden (Mapping, die Buchstabenabfolge der
mnemonischen Kürzel wird auf einen Zahlenwert abgebildet). Die feste Zuordnung von
Operationscodes zu Mnemoniks steht auch in den Tabellen von
Übersicht. Die Zahlenwerte des Operationscodes (z.B.
dezimal 60 für die Mnemonik istore_1) stehen dann an entsprechender
Stelle in der Klassendatei bzw. beim verwendeten einfachen Beispiel-Compiler innerhalb
der Konsolenausgabe. Ein Compiler realisiert mehrere aufeinanderfolgende Arbeitsabschnitte.
Ein Übersetzter setzt sich aus einer Analysephase (lexikalische Analyse, syntaktische
Analyse und semantische Analyse) und einer Synthesephase zusammen. Die Synthesephase
besteht i.a. auch aus mehreren Schritten zur Erzeugung eines Bytecodes (mitunter
ein Zwischencode) bzw. einem nativen Code (der erzeugte Maschinencode kann direkt
von der Hardware-/Betriebssystem-Kombination ausgeführt werden). Auf die verschiedenen
Phasen eines Compilers soll an dieser Stelle jedoch nicht näher eingegangen werden.
Damit Java-Bytecode z.B. einen Intel-Prozessor steuern kann, müsste Aufgrund
einer anderen Prozessorarchitektur der Bytecode nochmal auf einen speziellen
Intel-Maschinencode umgesetzt werden. Diese Aufgabe kann durch die JVM übernommen
werden (die JVM beinhaltet eine Ausführungseinheit für Java-Bytecode).
Die Java Virtual Machine (JVM) ist ein Bestandteil der Java-Laufzeitumgebung
(engl. Runtime Environment, JRE). Die JRE beinhaltet daneben noch Klassenbibliotheken
und andere Komponenten. Die Laufzeitumgebung ist notwendig, damit in Java geschriebene
Programme ausgeführt werden können. JREs (JVMs) sind für unterschiedliche
Hardware-Betriebssystem-Kombinationen (z.B. i586-Windows, amd64-Linux) erhältlich
und können unter java.com
 oder unter den Downloadseiten von
java.sun.com
heruntergeladen werden (JRE ist Bestandteil des JDK).
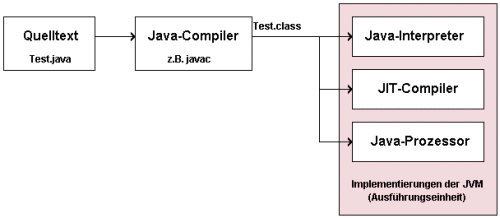
Die folgende Abbildung zeigt die unterschiedlichen Möglichkeiten, mit denen der
Bytecode innerhalb einer Klassendatei ausgeführt werden kann. Dabei wird grundsätzlich
zwischen einer Softwarelösung (Bytecode- bzw. Java-Interpreter und JIT-Compiler)
und einer Hardwarelösung (Java-Prozessor) unterschieden.
oder unter den Downloadseiten von
java.sun.com
heruntergeladen werden (JRE ist Bestandteil des JDK).
Die folgende Abbildung zeigt die unterschiedlichen Möglichkeiten, mit denen der
Bytecode innerhalb einer Klassendatei ausgeführt werden kann. Dabei wird grundsätzlich
zwischen einer Softwarelösung (Bytecode- bzw. Java-Interpreter und JIT-Compiler)
und einer Hardwarelösung (Java-Prozessor) unterschieden.
Hot Spots im Bytecode
Java-Anwednungen werden mit Hilfe des Befehls java gestartet.
Danach wird zunächst der Bytecode Schritt für Schritt interpretiert. Während der
Interpretation wird der Bytecode analysiert, um festzustellen, welche Programmabschnitte
besonders oft benötigt werden bzw. welche Elemente eine schnelle Ausführung des
Programms "behindern". Abschnitte im Bytecode, die besonders auf die Laufzeit
eines Programms niederschlagen werden als Hot Spots bezeichnet.
Um den Bytecode innerhalb von Hot Spots schneller als durch einen Interpreter
abarbeiten zu können, werden JIT-Compiler mit HotSpot-Optimierung eingesetzt (JIT
steht dabei für Just In Time, dt. gerade rechtzeitig). Der JIT-Compiler übersetzt
während der Laufzeit des Programms die Hot Spots in einen nativen Maschinencode
der zugrundelegenden Hardware, der durch den real vorhandenen Prozessor dirket
verarbeitet werden kann. Ein Teil des Bytecodes wird also durch einen Interpreter
zur Ausführung gebracht und der andere Teil (Hot Spots) wird aus Performancegründen
direkt in nativen Maschinencode compiliert. Dabei stellt das JDK (ab Version 5)
zwei unterschiedliche Implementierungen der Java Virtual Machine zur Verfügung:
Java HotSpot Client VM (client VM) und Java HotSpot Server VM (server VM). Die
voreingestellte VM für z.B. i586-Windows ist die client VM, die konzipiert wurde,
um vorallem die Startzeit einer Anwedung zu reduzieren. Die server VM startet
hingegen langsamer als die client VM, dafür ist aber die Programmausführung schneller.
Innerhalb der client VM und der server VM kommen unterschiedliche adaptive Compiler
zum Einsatz: Java HotSpot Client Compiler und Java HotSpot Server Compiler. Durch
die stattfindende HotSpot-Optimierung wird die JVM auch als Java HotSpot VM
bezeichnet.
Java-Prozessor
Die Realisierung der virtuellen Java Maschine in Hardware wird
auch als Java-Prozessor bezeichnet. Der
picoJava
Mikroprozessor von Sun Microsystems ist solch eine Hardwarerlösung der JVM. picoJava
kann Java-Bytecode direkt verarbeiten (der Bytecode wurde sozusagen in Hardware
"gegossen"). Der Java-Compiler javac der Bytecode generiert ist in
diesem Fall zugleich auch ein nativer Compiler, da der Java-Bytecode zugleich
Maschinencode ist und direkt durch den Prozessor picoJava ausgeführt werden kann.
Eine Software-Implementierung der JVM bietet den Vorteil der Kostenersparnis, da
effiziente Sofware, die auf gängige ausgereifte Prozessoren zurückgreift, relativ
leicht erstellbar und einsetzbar ist.
Java Virtual Machine Threads
Die JVM ist eine abstrakte Maschine und eine Implementation dieser fungiert
auch als Laufzeit-Interpreter des Bytecodes. Die JVM weiß grundsätzlich nichts von
einer Java-Programmiersprache, sondern kennt nur ein bestimmtes binäres Format
(Class File Format). Eine Klassendatei enthält u.a. die Befehle für die JVM, die
durch Bytes kodiert sind (Operationscode-Byte und eventuell vorhandene nachfolgende
Operandenbytes). Eine JVM (JRE) wird mit Hilfe der java-Anweisung
gestartet. Die hinter dieser Startanweisung angegebene Klassendatei wird geladen
und es wird versucht eine vorhandene main-Methode der Klasse aufzurufen.
Ist diese nicht vorhanden wird eine Fehlermeldung ausgegeben. Die JVM verlangt also
beim Start eine Methode main, mit dem folgenden Aussehen:
public static void main(String args[])
Die Hauptmethode muss mit public und static
deklariert sein und darf keinen Wert zurückgeben (es muss also void
angegeben werden). Die Methode muss außerdem einen String-Array als
einzigen Parameter besitzen. Genauer gesagt wird eine Java Virtual Machine durch
den Start eines Threads auf einer main-Methode einer Klassendatei
gestartet. Ein Thread ist dabei ein eigenständiger Programmteil, der neben anderen
Threads quasi gleichzeitig ablaufen kann. Die JVM wird beendet, wenn alle Threads
beendet wurden oder wenn in einem Thread der Aufruf System.exit erfolgt
ist. Dabei wird ein Thread beendet, wenn das Ende derjenigen Methode erreicht ist,
auf der der Thread gestartet wurde.
Jeder Thread der virtuellen Java-Maschinen verfügt über einen Programmzähler (PC, program counter). Er beinhaltet die Adresse des aktuell ausgeführten JVM-Befehls. Nachdem ein Thread gestartet wurde, wird auch ein Java Virtual Machine Stack für diesen Thread erzeugt, auf dem sogenannte Frames abgelegt werden können. Ein Frame hat u.a. die Aufgabe Daten zu speichern. Ein neuer Frame wird jedesmal angelegt, wenn eine Methode aufgerufen wird. Nachdem die Methode abgearbeitet wurde, wird auch der zugehörige Frame wieder eliminiert bzw. der durch den Frame belegte Speicherplatz wird wieder freigegeben. Jeder Frame besteht u.a. aus einem Array zur Speicherung von lokalen Variablen der Methode und einem Operandenstack (LIFO-Stack, last in first out). Die beiden genannten Bestandteile des Frames werden zur Ausführung der Methode benötigt. Für das Array zur Speicherung von lokalen Variablen gelten einige Bestimmungen. Ist die aufgerufene Methode nicht statisch, dann steht im ersten Eintrag des Arrays eine Referenz auf das zur Methode gehörende Objekt (this-Zeiger). Die Parameter der aufgerufenen Methode werden im Anschluss an den möglichen this-Zeiger in das Array gespeichert. Innerhalb der Methode deklarierte (lokale) Variablen werden wiederum nach den Methoden-Parametern eingetragen. Bei statischen Methoden ohne Parameter stehen eventuell vorhanden lokale Methoden-Variablen hingegen an erster Stelle im Array (Index 0). Der Operandenstapel eines Frames bzw. einer Methode wird u.a. von JVM-Befehlen genutzt, die auf einer bestimmten Anzahl von Operanden operieren. So werden z.B. die vorher durch entsprechende Anweisungen auf den Stapel gelegte Zahlenwerte durch einen Additions-Befehl herunter genommen, addiert und das Ergebnis wird danach automatisch wieder an die oberste Stelle des Operandenstacks gelegt.

Heap einer JVM
Eine virtuelle Java-Maschine hat einen Heap, wobei dieser von allen Threads
genutzt wird. Der Heap stellt zur Laufzeit u.a. Speicherplatz für die Instanzen von
Klassen zur Verfügung. Bestandteil eines Heap ist ein Methodenbereich (Method Area),
der den Bytecode der einzelnen compilierten Methoden enthält. Eine
.class-Datei beinhaltet einen zusammenhängenden Bereich zur Speicherung
von Daten (Konstantenpool), auf die vom Methodenbereich heraus zugegriffen wird.
Ein Konstantenpool eines Heap (Runtime Constant Pool) ist eine Laufzeitrepräsentation
des Konstantenpools einer Klassendatei.