Bei SQL-Schlüsselwörtern wie z.B. CREATE wird nicht zwischen
Groß- und Kleinschreibung unterschieden. Es sind daher auch Schreibweisen wie
create, Create oder CrEaTe zulässig und
gleichwertig. Es bietet sich aber an, SQL-Schlüsselwörter durch Großbuchstaben
hervorzuheben. SQL lässt sich in mehrere Sprachgruppen unterteilen. Eine
Sprachgruppe wird mit "Data Definition Language" (DDL) bezeichnet; die
CREATE TABLE-Anweisung gehört beispielsweise zu dieser Gruppe.
Innerhalb von SQL-Datenbanken werden Schemata verwendet, um Tabellen, in denen
sich die eigentlichen Daten befinden, zu gruppieren. Es können mehrere Schemata
innerhalb eines relationalen DBMS vorhanden sein. In jedem dieser Schemata können
Tabellen vorhanden sein, aber i.a. keine weiteren Schemata. JDBC unterstützt auch
sogenannte Kataloge, die wiederum als Übergruppierung von Schemata dienen sollen
(viele DBMS verwenden aber keine Kataloge). Weitere SQL-Sprachgruppen sind:
"Data Query Language" (DQL) zur Abfrage von Daten und "Data Manipulation Language"
(DML) zur Manipulation von Daten (z.B. Datenänderungen). Bei der Syntax-Beschreibung
von SQL-Anweisungen wird eine modifiziert Backus-Naur-Form (BNF) mit den folgenden
Metasymbolen verwendet:
Symbol Bedeutung | "oder" - Auswahl von Elementen möglich [ ] Das Klammerpaar schließt optinale Element ein * Element müssen nicht und können mehrmals verwendet werden { } Zusammenfassen von Elementen, damit die Symbole |, [], * verwendet werden können
Die Syntax zum Erzeugen einer Tabelle lautet wie folgt:
CREATE TABLE tableName ( columnDefinition [, columnDefinition]* [, tableConstraint]* )
Eine Spaltendefinition lässt sich aus folgender Ableitungsregel bestimmen:
(1) columnDefinition ::= columnName dataType
[columnConstraint]*
[{DEFAULT {constantExpression | NULL}}
| generatedColumnSpec]Für jede Spalte wird ein Name und ein Datentyp angegeben. Der Spaltenname darf nur einmal innerhalb der Tabelle auftreten und es muss mindestens eine Spalte definiert werden. Mehrere Spaltendefinitionen werden durch Kommata voneinander getrennt.
Die Datentypangabe hinter den Spaltennamen legt den SQL-Datentyp der
Tabellenspalte fest. Es gibt zum Teil größere Unterschiede zwischen den SQL-Typen,
die von den einzelnen DBMS unterstützt werden. So lautet z.B. ein SQL-Typname beim
DBMS Derby VARCHAR FOR BIT DATA, wohingegen bei einem Oracle DBMS
RAW verwendet wird. Die in der Bezeichnung unterschiedlichen SQL-Typen
haben die gleiche Semantik und es kann für beide der einheitliche JDBC-Typ
BINARY angegeben werden, sie werden sozusagen beide auf einen JDBC-Typ
abgebildet (mapping). JDBC definiert innerhalb der Klasse java.sql.Types
die generischen (allgemeinen) SQL-Typ-Bezeichner (JDBC-Typen). JDBC definiert
weiter ein "Standard-Mapping" von JDBC-Typen zu Java-Typen. Es wird z.B.
normalerweise der JDBC-Typ INTEGER auf den primitiven Java-Datentyp
int abgebildet. Ein mitunter datenbankspezifischer SQL-Typ wird
sozusagen über den Umweg eines zugehörigen JDBC-Typs auf einen Java-Typ abgebildet.
SQL-Typ <---> JDBC-Typ <---> Java-Typ
Viele SQL-Typnamen des DBMS Derby stimmen mit den JDBC-Typnamen überein. Die folgende Anordnung zeigt die Zuordnungen der einzelnen Datentypen (die genannten SQL-Typen sind eine größere Auswahl der vom DBMS Derby unterstützten Datentypen):
SQL-Typ (Derby) JDBC-Typ Java-Typ SMALLINT SMALLINT short INTEGER INTEGER int BIGINT BIGINT long REAL REAL float DOUBLE DOUBLE double DECIMAL DECIMAL java.math.BigDecimal CHAR CHAR String VARCHAR VARCHAR String DATE DATE java.sql.Date TIME TIME java.sql.Time TIMESTAMP TIMESTAMP java.sql.Timestamp CHAR FOR BIT DATA BINARY byte[] VARCHAR FOR BIT DATA VARBINARY byte[] BLOB BLOB java.sql.Blob CLOB CLOB java.sql.Clob
Beim einigen SQL-Typen sind zusätzliche Angaben möglich oder nötig, so ist
z.B. bei VARCHAR eine zusätliche Längenangabe nötig, die in einem
runden Klammerpaar angegeben wird. Bei einigen Typen können auch verschiedene
Bezeichnungen angegeben werden; die Angabe INT ist z.B. gleichbedeutend
mit INTEGER.Welche Syntax für die einzelnen Typen gilt verdeutlicht
die folgende Ableitungsregel für SQL-Datentypen:
(2) dataType ::= SMALLINT | { INTEGER | INT } | BIGINT |
REAL | DOUBLE | { DECIMAL | DEC } [(precision [, scale ])] |
CHAR[ACTER] [(length)] | { VARCHAR | CHAR VARYING
| CHARACTER VARYING }(length) |
DATE | TIME | TIMESTAMP |
{ CHAR | CHARACTER }[(length)] FOR BIT DATA |
{ VARCHAR | CHAR VARYING | CHARACTER VARYING }
(length) FOR BIT DATA |
{ BLOB | BINARY LARGE OBJECT } ( length [{K |M |G }])) |
{ CLOB | CHARACTER LARGE OBJECT } (length [{{K |M |G}]))Ein einfaches Beispiel für eine Tabellenerzeugung könnte wie folgt aussehen:
CREATE TABLE personen (
id INTEGER,
name VARCHAR(50),
vorname VARCHAR(50),
passbild BLOB(100 K),
geschlecht CHAR(1)
)
Erläuterung zum SQL-Typ CHAR FOR BIT DATA
Ein CHAR FOR BIT DATA-Typ ermöglicht es eine gewisse Anzahl
einzelner Bytes (Bits) zu speichern. Es soll z.B. die Bitfolge
11001010 11111110 in einer Tabellenspalte abgelegt werden. Dies kann
erfolgen, indem zunächst eine Tabelle mit einer entprechenden Spaltendefinition
erzeugt wird und anschließend über eine Einfügeanweisung die Beispiel-Bitfolge
in die Tabelle aufgenommen wird (ausgehend von einem Statement-Objekt
stmt):
stmt.executeUpdate("CREATE TABLE test (b CHAR(3) FOR BIT DATA)");
stmt.executeUpdate("INSERT INTO test VALUES (x'cafe')");Dabei entpricht der Beispiel-Bitfolge 11001010 11111110 der
hexadezimale Wert 0xcafe. Das Präfix 0x deuted an, dass
die nachfolgenden Buchstaben bzw. Ziffern hexadezimal zu werten sind. Die Notation
bei der SQL-Einfügeanmweisung verlangt x'cafe'. Die empfohlene
Methode für das Abfragen von CHAR FOR BIT DATA-Werten ist
ResultSet.getBytes. Das folgende Programmfragment ruft die zuvor
gespeicherte Beispiel-Bitfolge ab und gibt diese in Binärdarstellung aus:
ResultSet rs = stmt.executeQuery("SELECT * FROM test");
rs.next();
byte[] b = rs.getBytes(1);
for (int j = 0; j < b.length; j++) {
int i = (b[j] & 0x7f) + (b[j] < 0 ? 128 : 0);
String s = Integer.toBinaryString(i);
StringBuffer sb = new StringBuffer("00000000");
sb = sb.replace(8 - s.length(), 8, s);
System.out.print(sb + " ");
}Zunächst wird mit getBytes ein Byte-Array mit den drei
Einträgen -54, -2 und 32 erhalten. Der Wertebereich des primitiven Datentyps
byte liegt bekanntlich im Bereich von -128 bis 127. Der dezimale
Wert eines Bytes ist negativ, falls das erste Bit (von links) des Bytes 1 ist.
Die Anweisungen innerhalb der for-Schleife dienen der Umwandlung
der vorzeichenbehafteten Byte-Werte in Binärdarstellung. Die Ausgabe würde wie
folgt aussehen:
11001010 11111110 00100000
Die Bitfolge 00100000 (hexadezimal 0x20) erscheint zusätzlich
zur ursprünglich gespeicherten Folge. Der Werte 0x20 ist ein Füllwert, da nur
zwei Bytes gespeichert wurden ("reserviert" wurden 3 Bytes).
Erläuterung zum SQL-Typ BLOB
Der SQL-Typ BLOB (Binary Large Objekts) ermöglicht den Umgang
mit größere Datenmengen (z.B. Bilddateien). Beim DBMS Derby steht eine
BLOB-Länge von 2.147.483.647 Bytes zur Verfügung. Bei der Längenangabe
besteht die Möglichkeit ein K, M oder G anzuhängen. Die Suffixe stehen dabei für
Kilo-, Mega- und Gigabytes. Wird eine Spalte einer Tabelle als BLOB
ausgewiesen, speichert das DBMS die binären Daten separiert ab und hinterlässt in
der Tabellenspalte eine Referenz (Zeiger) auf die eigentlichen Daten. Das Interface
java.sql.Blob ist die Repräsentation (Mapping) des SQL-Typs
BLOB und stellt u.a. die folgenden Methoden bereit:
java.sql Interface Blob Methode: InputStream getBinaryStream() byte[] getBytes(long pos, int length) long length()
Die Methode getBinaryStream gibt einen InputStream
zurück, durch den die binären Daten erhalten werden können. Handelt es sich z.B.
um eine Bilddatei, können die Daten des Stromes mittels der Methode
ImageIO.read in ein BufferedImage-Objekt eingelesen
werden. Mit der Methode getBytes kann ein Byteausschnitt abgefragt
werden. Der Paramter pos gibt die Position des ersten Bytes des
BLOB-Wertes an, das extrahiert werden soll. Der zweite Parameter
length bestimmt die Anzahl der auszulesenden Bytes. Wieviele Bytes
mit Hilfe eines BLOB-Objekts gespeichert wurde, kann durch Aufruf der
Methode length ermittelt werden. Das folgende kurze Listing legt die
Tabelle personen innerhalb einer Datenbank des DBMS Derby an. Eine
Tabellenspalte ist mit dem BLOB-Typ ausgewiesen und wird mit einer
kleinen Bilddatei belegt. Nachdem die einzelnen Spalten gefüllt wurden, werden im
Beispiel alle Daten aus der Tabelle ausgelesen und in einem Swing-Fenster graphisch
dargestellt. Um das DBMS Derby verwenden zu können, muss das Archiv
derby.jar im Klassenpfad liegen. Ein Startaufruf der Applikation
könnte wie folgt aussehen:
java -classpath .;c:/user/db-derby/lib/derby.jar BLOBExample
Im Beispiellisting wird eine kleine
Bilddatei
 im JPEG-Format verwendet. Die Grafikdatei wird aus einem Ordner
heraus aufgerufen (
im JPEG-Format verwendet. Die Grafikdatei wird aus einem Ordner
heraus aufgerufen (images/lena100x100.jpg). Der Ordner sollte
erstellt und die Grafik entsprechend kopiert werden, damit das Beispiel richtig
funktioniert.
Listing 6.2. BLOBExample.java
/* * BLOBExample.java * */ import java.sql.*; import java.awt.*; import java.awt.image.*; import java.io.*; import javax.imageio.*; import javax.swing.*; public class BLOBExample extends JPanel { int id; String name; String vorname; BufferedImage bi; String geschlecht; public void createAndShowGUI(JPanel panel) { JFrame.setDefaultLookAndFeelDecorated(true); JFrame frame = new JFrame("BLOBExample"); frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); frame.add(panel); frame.setSize(400, 170); frame.setVisible(true); } public void sqlMethod() { try { Class.forName("org.apache.derby.jdbc.EmbeddedDriver"); } catch (ClassNotFoundException e) { System.out.println(e.toString()); System.exit(1); } try { Connection con = DriverManager.getConnection("jdbc:derby:derbyDB;create=true"); Statement stmt = con.createStatement(); // Tabelle personen bereits vorhanden? DatabaseMetaData meta = con.getMetaData(); ResultSet rs = meta.getTables(null, "APP", null, null); while (rs.next()) { if (rs.getString("TABLE_NAME").toLowerCase().equals("personen")) { stmt.executeUpdate("DROP TABLE personen"); } } String strCreateTable = "CREATE TABLE personen (" + "id INTEGER," + "name VARCHAR(50)," + "vorname VARCHAR(50)," + "passbild BLOB(100 K)," + "geschlecht CHAR(1)" + ")"; stmt.executeUpdate(strCreateTable); System.out.println("Tabelle personen angelegt"); File f = new File("images/lena100x100.jpg"); int flength = (int)f.length(); FileInputStream fin = null; try { fin = new FileInputStream(f); } catch (FileNotFoundException e) { System.out.println(e.toString()); } PreparedStatement ps = con.prepareStatement( "INSERT INTO personen VALUES (?, ?, ?, ?, ?)"); ps.setInt(1, 1); ps.setString(2, "jpg"); ps.setString(3, "lena"); ps.setBinaryStream(4, fin, flength); ps.setString(5, "w"); ps.executeUpdate(); rs = stmt.executeQuery("SELECT * FROM personen"); rs.next(); id = rs.getInt(1); name = rs.getString(2); vorname = rs.getString(3); Blob bl = rs.getBlob(4); InputStream in = bl.getBinaryStream(); try { bi = ImageIO.read(in); } catch (IOException e) { System.out.println(e.toString()); } geschlecht = rs.getString(5); stmt.executeUpdate("DROP TABLE personen"); System.out.println("Tabelle personen geloescht"); rs.close(); ps.close(); stmt.close(); con.close(); } catch (SQLException e) { while (e != null) { System.out.println(e.toString()); System.out.println("ErrorCode: " + e.getErrorCode()); System.out.println("SQLState: " + e.getSQLState()); e = e.getNextException(); } } } public static void main(String[] args) { final BLOBExample be = new BLOBExample(); be.sqlMethod(); Runnable runner = new Runnable() { public void run() { be.createAndShowGUI(be); } }; SwingUtilities.invokeLater(runner); } public void paintComponent(Graphics g) { super.paintComponent(g); Graphics2D g2 = (Graphics2D)g; g2.drawImage(bi, null, 10, 10); g2.drawString("id: " + Integer.toString(id), 150, 20); g2.drawString("Name: " + name, 150, 40); g2.drawString("Vorname: " + vorname, 150, 60); g2.drawString("Geschlecht: " + geschlecht, 150, 80); } }
Das Beispiel erzeugt ein Ausgabefenster:
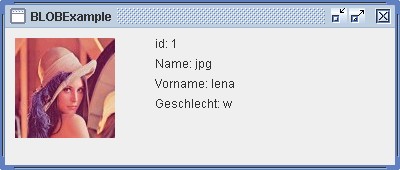
Innerhalb der Tabellendefinition können Randbedingungen (engl. constraints)
aufgenommen werden. Es sind zwei Arten von Randbedingungen möglich:
Spaltenrandbedingungen sind einer Spalte fest zugeordnet und Tabellenrandbedingungen
können auch für mehrere Spalten gelten. Der Constraint-Zusatz ist ein optionaler Teil
der CREATE TABLE-Anweisung. Ein Constraint ist eine Regel, welche von
den Daten erfüllt werden muss. Dabei ist es oftmals möglich eine Spaltenrandbedingung
auch als eine Tabellenrandbedingung zu formulieren. Für eine Spaltenrandbedingung
kann die folgende Ableitungsregel angegeben werden:
(3) columnConstraint ::= NOT NULL |
{[CONSTRAINT constraintName]
{ CHECK (searchCondition) |
{ UNIQUE |
PRIMARY KEY |
REFERENCES tableName [...] }
}}Eine Tabellenrandbedingung genügt der folgenden Ableitungsregel:
(4) tableConstraint ::= [CONSTRAINT constraintName]
{ CHECK (searchCondition) |
{ UNIQUE (columnName [,columnName]*) |
PRIMARY KEY (columnName [,columnName]*) |
FOREIGN KEY (columnName [,columnName]*)
REFERENCES tableName [...] }
}
NOT NULL-Randbedingung
Eine NOT NULL-Randbedingung kann direkt hinter der Datentypangabe
der Tabellenspalte angegeben werden:
vorname VARCHAR(50) NOT NULL
Diese Spaltenrandbedingung erfordert, dass die Spalte mit einem definierten
Wert belegt wird - eine Belegung mit dem Schlüsselwort null ist
nicht möglich.
Bezeichnung einer Randbedingung (constraint)
Eine Randbedingung kann mit einem Namen versehen werden. Dies kann sinnvoll sein, wenn eine Randbedingung verletzt wird, da bei einer entsprechenden SQL-Fehlerbehandlung der Name der Randbedingung mit angegeben werden kann.
CHECK-Randbedingung
Bei den folgenden SQL-Anweisungen wurde eine
CHECK-Spaltenrandbedingung verwendet. Sie überprüft beim Belegen der
Spalte mit einem Wert, ob dieser entweder 'm' oder 'w' ist. Ist dies nicht der
Fall wird eine SQLException ausgelöst.
CREATE TABLE personen (
id INTEGER,
name VARCHAR(50),
vorname VARCHAR(50),
passbild BLOB(100 K),
geschlecht CHAR(1) CHECK (geschlecht IN ('m', 'w'))
)
INISERT INTO personen VALUES (1, 'im Glueck', 'Hans', null , 'x')Bei Verwendung der obigen SQL-Anweisungen innerhalb eines Java-Programms mit entsprechender Fehlerbehandlung würde z.B. die folgende Fehlermeldung ausgegeben (Derby):
SQL Exception: The check constraint 'SQL060510092203260' was violated while
performing an INSERT or UPDATE on table 'APP.PERSONEN'.Das Präfix APP. vor dem Tabellennamen ist die Bezeichnug eines
Tabellenschemas. Allen Tabellen, bei denen bei der Erzeugung keine Schemaangabe
gemacht wird, werden automatisch dem Schema APP zugeordnet
(voreingestelltes Benutzerschema). So ist z.B.
CREATE TABLE APP.personen (...) gleichbedeutend mit
CREATE TABLE personen (..). Da die CHECK-Randbedingung
nicht mit einem Namen versehen wurde, wird bei der Fehlermeldung eine
Nummernbezeichnung ('SQL0605...') für die verletzte Randbedingung
generiert. Wird hingegen
geschlecht CHAR(1) CONSTRAINT gesch_ck CHECK (geschlecht IN ('m', 'w'))bei der Spaltendefinition verwendet lautet die Fehlermeldung:
SQL Exception: The check constraint 'GESCH_CK' was violated while
performing an INSERT or UPDATE on table 'APP.PERSONEN'.
UNIQUE-Randbedingung
Tabellenspalten, die mit dem Schlüsselwort UNIQUE gekennzeichnet
werden, dürfen Werte enthalten, die nur einmal in dieser Spalte vorkommen und müssen
zusätzlich (Derby) mit der Randbedingung NOT NULL versehen werden.
Innerhalb der folgenden CREATE TABLE-Anweisung ist die zweite Spalte
mit UNIQUE versehen:
CREATE TABLE personen (
id INTEGER,
name VARCHAR(50) NOT NULL UNIQUE,
vorname VARCHAR(50) NOT NULL,
passbild BLOB(100 K),
geschlecht CHAR(1)
)
INSERT INTO personen VALUES (1, 'im Glueck', 'Hans', null , 'm')
INSERT INTO personen VALUES (2, 'Dampf', 'Hans', null , 'm')
INSERT INTO personen VALUES (3, 'im Glueck', 'Harald', null , 'm') //Fehler!Die ersten beiden Einfügeanweisungen werden noch problemlos ausgeführt, da
die zweite Tabellenspalte mit unterschiedlichen Inhalten gefüllt wird. Bei der
dritten INSERT INTO-Anweisung soll die zweite Spalte (dritte
Tabellenzeile) noch einmal mit dem Wert 'im Glueck' belegt werden,
der aber bereits in der zweiten Spalte der ersten Tabellenzeile steht. Die
UNIQUE-Randbedingung wurde dadurch verletzt und es wird eine
Fehlermeldung ausgegeben:
SQL Exception: The statement was aborted because it would have caused a duplicate
key value in a unique or primary key constraint or unique index
identified by 'SQL060510002431670' defined on 'PERSONEN'.Es bietet sich im Beispiel an, eine Personentabelle zuzulassen, die gleiche
Personennamen zulässt, wenn sich die jeweiligen Personenvornamen unterscheiden.
Bei einer derartig strukturierten Tabelle könnt eine
UNIQUE-Tabellenbschränkung (tableConstraint) wie folgt verwendet
werden:
CREATE TABLE personen (
id INTEGER,
name VARCHAR(50) NOT NULL,
vorname VARCHAR(50) NOT NULL,
passbild BLOB(100 K),
geschlecht CHAR(1),
UNIQUE (name, vorname)
)
INSERT INTO personen VALUES (1, 'im Glueck', 'Hans', null , 'm')
INSERT INTO personen VALUES (2, 'Dampf', 'Hans', null , 'm')
INSERT INTO personen VALUES (3, 'im Glueck', 'Harald', null , 'm')
INSERT INTO personen VALUES (4, 'im Glueck', 'Hans', null , 'm') //Fehler!Hier würden die ersten drei Einfügeanweisungen ausgeführt und lediglich bei der letzten Einfügeanweisung wäre eine Fehlermeldung zu erwarten.
PRIMARY KEY-Randbedingung
Eine Primärschlüsselrandbedingung ermöglicht eine eindeutige Identifikation
einer jeden Tabellenzeile. Wird die PRIMARY KEY-Randbedingung als
Spaltenrandbedingung verwendet kann nur eine Spalte als Primärschlüssel ausgewiesen
werden im Gegensatz zu einer UNIQUE-Randbedingung, bei der auch mehrere
Spalten derart notiert werden können. Innerhalb einer mit
PRIMARY KEY versehenen Spalte dürfen Werte nur einmal vorkommen und
der Spaltenwert null ist nicht zulässig.
CREATE TABLE personen (
id INTEGER NOT NULL PRIMARY KEY,
...
)
FOREIGN KEY-Randbedingung
Eine Fremdschlüsselrandbedingung schafft Abhängigkeiten zwischen mehreren
Tabellen (Tabellenspalten). Diese Randbedingung spezifiziert eine einzelne Spalte
(Spaltenrandbedingung) oder mehrere Spalten (Tabellenrandbedingung) einer
referenzierenden Tabelle als Fremschlüssel. Eine Tabelle, von dem eine Referenz
ausgeht (referenzierende Tabelle) wird auch als Kindtabelle und die Tabelle auf
die referenziert wird auch als Elterntabelle bezeichnet. Zum Beispiel soll die
Elterntabelle autoren erzeugt und mit einer Reihe gefüllt werden:
CREATE TABLE autoren (
name VARCHAR(50) NOT NULL PRIMARY KEY,
voname VARCHAR(50),
isbn VARCHAR(50)
)
INSERT INTO autoren VALUES ('im Glueck', 'Hans', 'ISBN 1-23456-789-0')Als nächstes soll die Kindtabelle personen angegeben werden,
die die Spalte mit dem Sapltennamen name als Fremdschlüssel ausweist
und eine Eintrag soll erfolgen:
CREATE TABLE personen (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(50) REFERENCES autoren(name),
vorname VARCHAR(50),
passbild BLOB(100 K),
geschlecht CHAR(1)
)
INSERT INTO personen VALUES (1, 'im Glueck', 'Hans', null , 'm')Die Schlüsselbezeichnung FOREIGN KEY wird zusätzlich zu
REFERENCES verwendet, wenn der Fremdschlüssel mehr als eine
Tabellenspalte beinhalten soll (Tabellenrandbedingung). Der Zusatz REFERENCES
legt fest, auf welche Spalte der Elterntabelle referenziert werden soll. Wird nur
der Tabellenname angegeben erfolgt eine automatische Festlegung der Referenz
auf die Spalte, die als Primärschlüssel ausgewiesen ist. Im Beispiel ist
name der Fremdschlüssel der Kindtabelle personen und
refernziert auf die Spalte mit dem Spaltennamen name der Elterntabelle
autoren. Damit die Fremdschlüsselrandbedingung nicht verletzt wird,
müssen die Werte der Fremdschlüsselspalte (Kindtabelle) mit den Werten
der als Primärschlüssel ausgewiesenen Spalte der Elterntabelle übereinstimmen.
Im Beispiel ist der Spaltenwert 'im Glueck' sowohl in der Kind-
als auch in der Elterntabelle vorhanden. Die vorgestellten SQL-Anweisungen zur
Tabellenverknüpfung mittels eines Fremdschlüssels sollen in ein lauffähiges kurzes
Java-Listing eingebettet werden. Das folgende Beispiel definiet einen Primärschlüssel
mit zwei Spalten (Tabellenrandbedingung) für die Tabelle autoren.
Der Fremdschlüssel der Tabelle personen beinhaltet ebenfalls zwei
Spalten und verweist auf die beiden Primärschlüsselspalten der Kindtabelle.
Das Beipiellisting kann wieder wie folgt gestartet werden:
java -classpath .;c:/user/db-derby/lib/derby.jar ForeignKeyExample
Listing 6.3. ForeignKeyExample.java
/* ForeignKeyExample.java */ import java.sql.*; public class ForeignKeyExample { public static void main(String[] args) { try { Class.forName("org.apache.derby.jdbc.EmbeddedDriver"); } catch (ClassNotFoundException e) { System.out.println(e.toString()); System.exit(1); } try { Connection con = DriverManager.getConnection( "jdbc:derby:derbyDB;create=true"); Statement stmt = con.createStatement(); // Tabellen personen, autoren bereits vorhanden? DatabaseMetaData meta = con.getMetaData(); ResultSet rs = meta.getTables(null, "APP", null, null); while (rs.next()) { if (rs.getString("TABLE_NAME").toLowerCase().equals("personen")) { stmt.executeUpdate("DROP TABLE personen"); } if (rs.getString("TABLE_NAME").toLowerCase().equals("autoren")) { stmt.executeUpdate("DROP TABLE autoren"); } } String strCreateTable = "CREATE TABLE autoren (" + "name VARCHAR(50) NOT NULL," + "vorname VARCHAR(50) NOT NULL," + "isbn VARCHAR(50)," + "PRIMARY KEY(name, vorname)" + ")"; stmt.executeUpdate(strCreateTable); stmt.executeUpdate("INSERT INTO autoren VALUES ('im Glueck', 'Hans', " + "'ISBN 1-23456-789-0')"); strCreateTable = "CREATE TABLE personen (" + "id INTEGER," + "name VARCHAR(50)," + "vorname VARCHAR(50)," + "passbild BLOB(100 K)," + "geschlecht CHAR(1)," + "FOREIGN KEY(name, vorname) REFERENCES autoren(name, vorname)" + ")"; stmt.executeUpdate(strCreateTable); stmt.executeUpdate("INSERT INTO personen VALUES (1, 'im Glueck', " + "'Hans', null , 'm')"); System.out.println("Tabellen angelegt"); stmt.executeUpdate("DROP TABLE personen"); stmt.executeUpdate("DROP TABLE autoren"); System.out.println("Tabellen geloescht."); rs.close(); stmt.close(); con.close(); } catch (SQLException e) { while (e != null) { System.out.println(e.toString()); System.out.println("ErrorCode: " + e.getErrorCode()); System.out.println("SQLState: " + e.getSQLState()); e = e.getNextException(); } } } }
Für einzelne Tabellespalten können Vorgabewerte innerhalb der
CREATE TABLE-Anweisung angegeben werden. Ein Vorgabewert wird dann
verwendet, wenn bei einer Einfügeanweisung nicht alle Spalten der Tabellenzeile
mit einem Wert belegt werden. Falls kein Wert mittels des DEFAULT-Zusatzes
innerhalb einer Spaltendefinition angegeben wurde, wird das Schlüsselwort
null als Default-Wert verwendet. Ist der SQL-Datentyp einer
Tabellenspalte SMALLINT, INTEGER, oder BIGINT,
können automatisch fortlaufende Nummernwerte für diese Spalten erzeugt und als
Spaltenwert verwendet werden, indem eine Zusatzangabe in der Spaltendefinition
angegeben wird, die der folgenden Ableitungsregel entspricht:
(5) generatedColumnSpec :== GENERATED {ALWAYS | BY DEFAULT} AS IDENTITY
[ (START WITH integerConstant
[,INCREMENT BY integerConstant]) ]Das nächste kurze Beispiel verwendet fest vorgegebene (mittels
DEFAULT-Zusatz) und automatisch generierte Spaltenwerte. Der
Startaufruf des Listings kann wie folgt erfolgen:
java -classpath .;c:/user/db-derby/lib/derby.jar GeneratedColumnValueExample
Listing 6.4. GeneratedColumnValueExample.java
/* * GeneratedColumnValueExample.java * */ import java.sql.*; public class GeneratedColumnValueExample { public static void main(String[] args) { try { Class.forName("org.apache.derby.jdbc.EmbeddedDriver"); } catch (ClassNotFoundException e) { System.out.println(e.toString()); System.exit(1); } try { Connection con = DriverManager.getConnection("jdbc:derby:derbyDB;create=true"); Statement stmt = con.createStatement(); // Tabelle personen bereits vorhanden? DatabaseMetaData meta = con.getMetaData(); ResultSet rs = meta.getTables(null, "APP", null, null); while (rs.next()) { if (rs.getString("TABLE_NAME").toLowerCase().equals("personen")) { stmt.executeUpdate("DROP TABLE personen"); } } String strCreateTable = "CREATE TABLE personen (" + "id INTEGER GENERATED BY DEFAULT AS IDENTITY " + "(START WITH 5, INCREMENT BY 5)," + "name VARCHAR(50) DEFAULT 'im Glueck'," + "vorname VARCHAR(50)," + "passbild BLOB(100 K) DEFAULT NULL," + "geschlecht CHAR(1)" + ")"; stmt.executeUpdate(strCreateTable); System.out.println("Tabelle angelegt"); stmt.executeUpdate("INSERT INTO personen (vorname) values ('Hans')"); stmt.executeUpdate("INSERT INTO personen (id, vorname) values (99, 'Harald')"); stmt.executeUpdate("INSERT INTO personen (name, vorname) values ('Dampf', 'Hans')"); rs = stmt.executeQuery("SELECT * FROM personen"); while (rs.next()) { System.out.println(rs.getInt(1) + ", " + rs.getString(2) + ", " + rs.getString(3) + ", " + rs.getBlob(4) + ", " + rs.getString(5)); } stmt.executeUpdate("DROP TABLE personen"); System.out.println("Tabelle geloescht."); rs.close(); stmt.close(); con.close(); } catch (SQLException e) { while (e != null) { System.out.println(e.toString()); System.out.println("ErrorCode: " + e.getErrorCode()); System.out.println("SQLState: " + e.getSQLState()); e = e.getNextException(); } } } }
Bei der Konsolenausgabe erscheinen die drei folgenden Zeilen:
5, im Glueck, Hans, null, null 99, im Glueck, Harald, null, null 10, Dampf, Hans, null, null
Der Wert für die erste Tabellenspalte wir automatisch generiert und verwendet,
falls bei einer Einfügeanweisung der ersten Spalte nicht explizit ein Wert zugewiesen
wird (siehe zweite Tabellenreihe). Der Zahlenwert startet mit 5 und erhöht sich
bei jeder weiteren Einfügung einer Zeile um 5). Die zweite Spalte hat einen Default-Wert
'im Glueck', der bei den ersten beiden Tabellenzeilen verwendet wurde.